
这两天,朋友圈几乎被 Seedance 2.0 的视频刷屏了,感觉人人都能当导演。不过,就在大家都在看热闹、讨论 AI 怎么颠覆好莱坞的时候,豆包大模型 2.0 的全家桶,刚刚正式发布了。
这也是豆包大模型自 2024 年 5 月正式发布以来首次跨代升级。
说实话,作为把 AI 当生产力工具的老韭菜,我最关心的其实就两点:能不能干活?能不能便宜点?对此,这次豆包大模型 2.0 版本的更新,给出的答案很朴实:读懂图表文档、看懂长视频、写出能用的代码,并且把价格打下来。

而且,这次不仅仅是一个单体模型的升级,而是一整套「组合拳」。
豆包大模型 2.0 系列包含 Pro、Lite、Mini 三款通用 Agent 模型和 Code 模型,灵活适配各类业务场景,其中现在打开豆包 App、电脑客户端或网页版,点击「专家模式」,即可第一时间体验全新升级的豆包大模型 2.0 Pro:
- 豆包 2.0 Pro:堆料狂魔,专攻深度推理和长链路任务,官方说法是全面对标 GPT-5.2 和 Gemini 3 Pro,
- 2.0 Lite:主打一个「既要又要」,性能和成本的平衡大师,综合能力已经反超了上一代的主力豆包 1.8。
- 2.0 Mini:低时延、高并发,专门给那些对成本极度敏感的场景准备的。
- Code 版(Doubao-Seed-2.0-Code):程序员特供,建议配合 IDE 工具 TRAE 食用,疗效更佳。
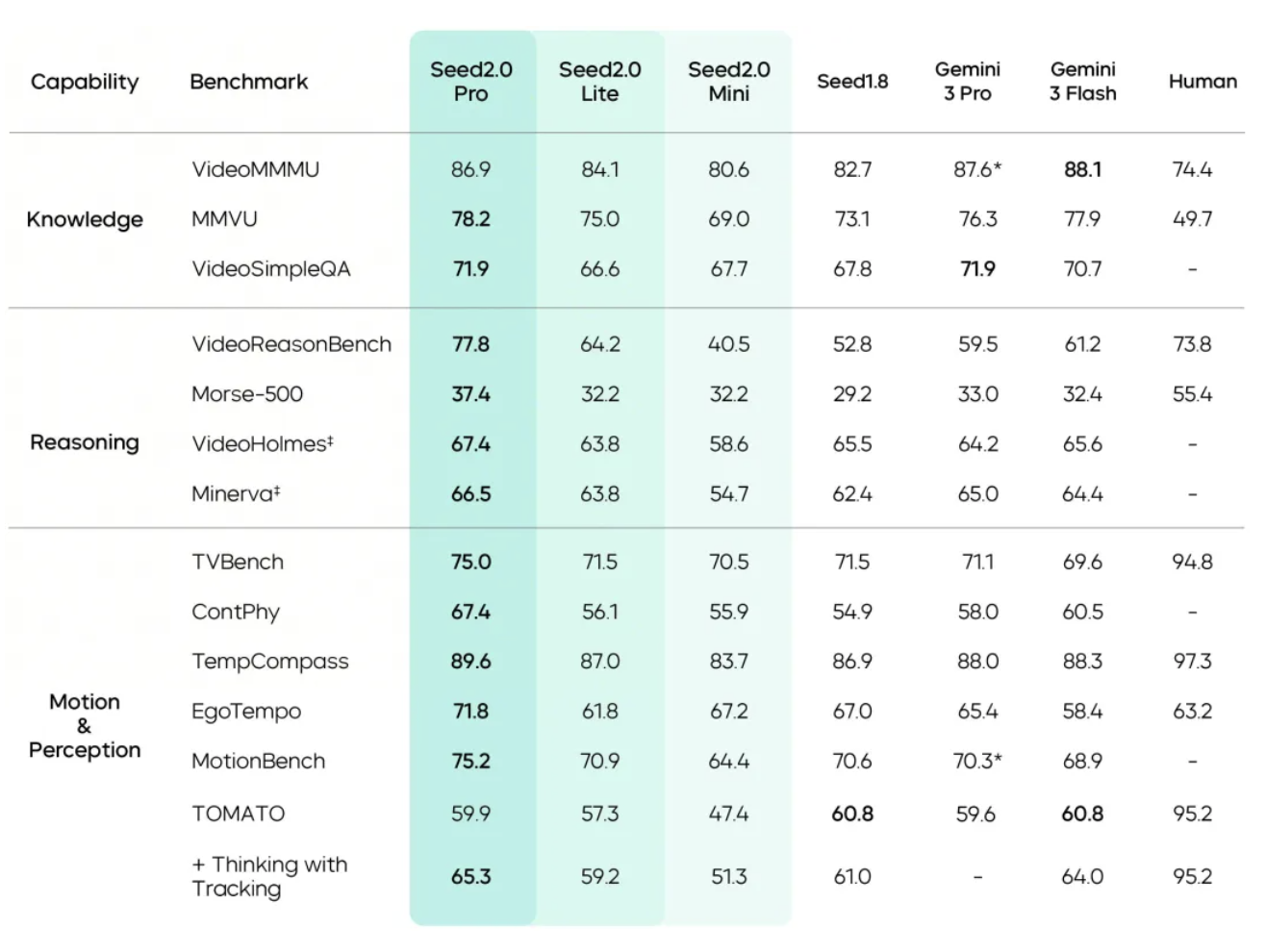
比人类还懂视频,豆包大模型 2.0 的多模态理解有多强?
如果说文本模型是 AI 的大脑,那么多模态理解就是它的眼睛。
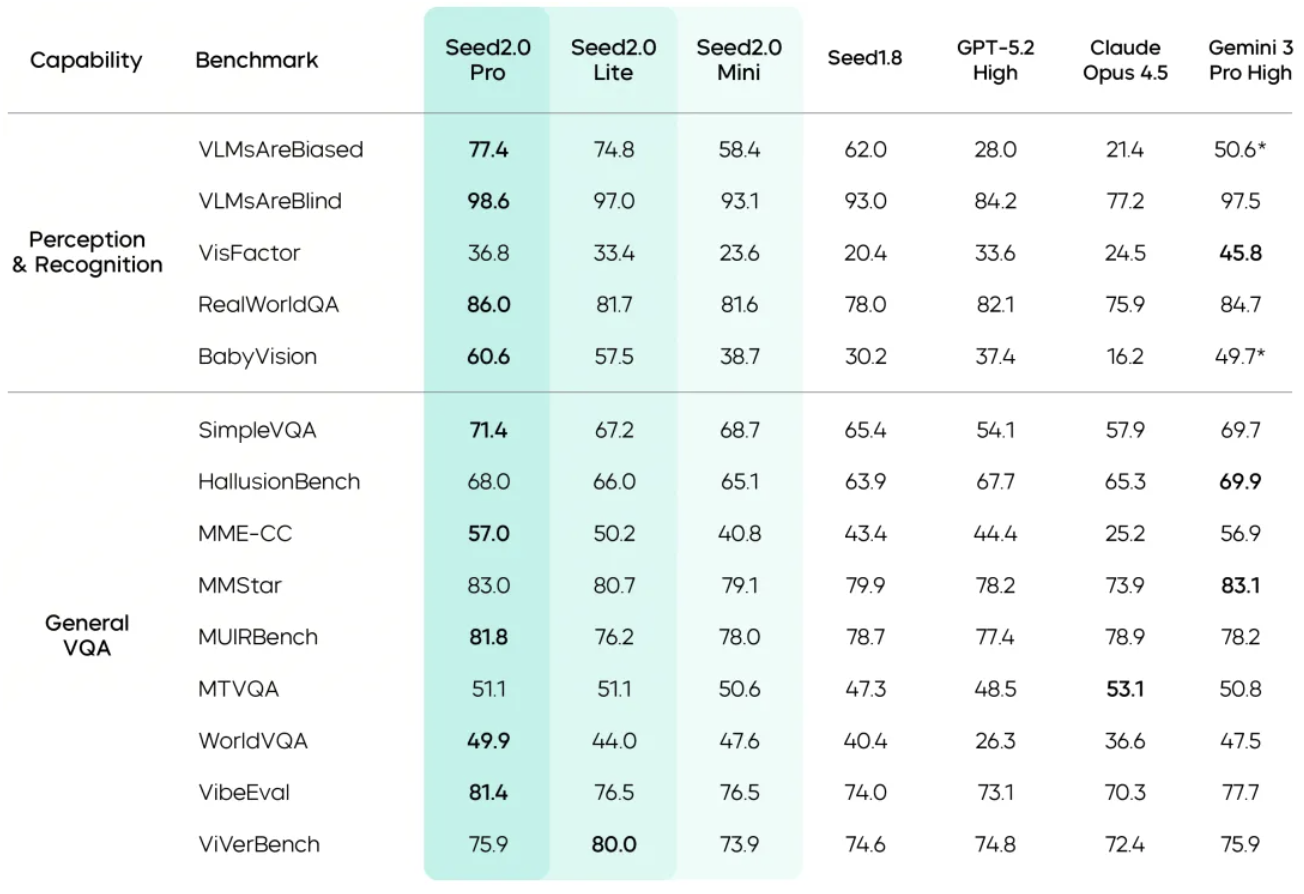
官方技术报告显示,豆包大模型 2.0 系列在 VLMsAreBiased、OmniDocBench 等基准上均取得了业界最高分。
数据很枯燥,我们找来了一张网友恶搞的「整活」图片——一瓶号称 「20 合一的男士洗发水」。瓶身上密密麻麻地堆砌着各种类型的产品。
扔给豆包 2.0 Pro 后,即便文字被截断,它依然通过上下文清晰识别。而且,它没有傻乎乎地介绍产品,而是明确指出这是一种「整活」。

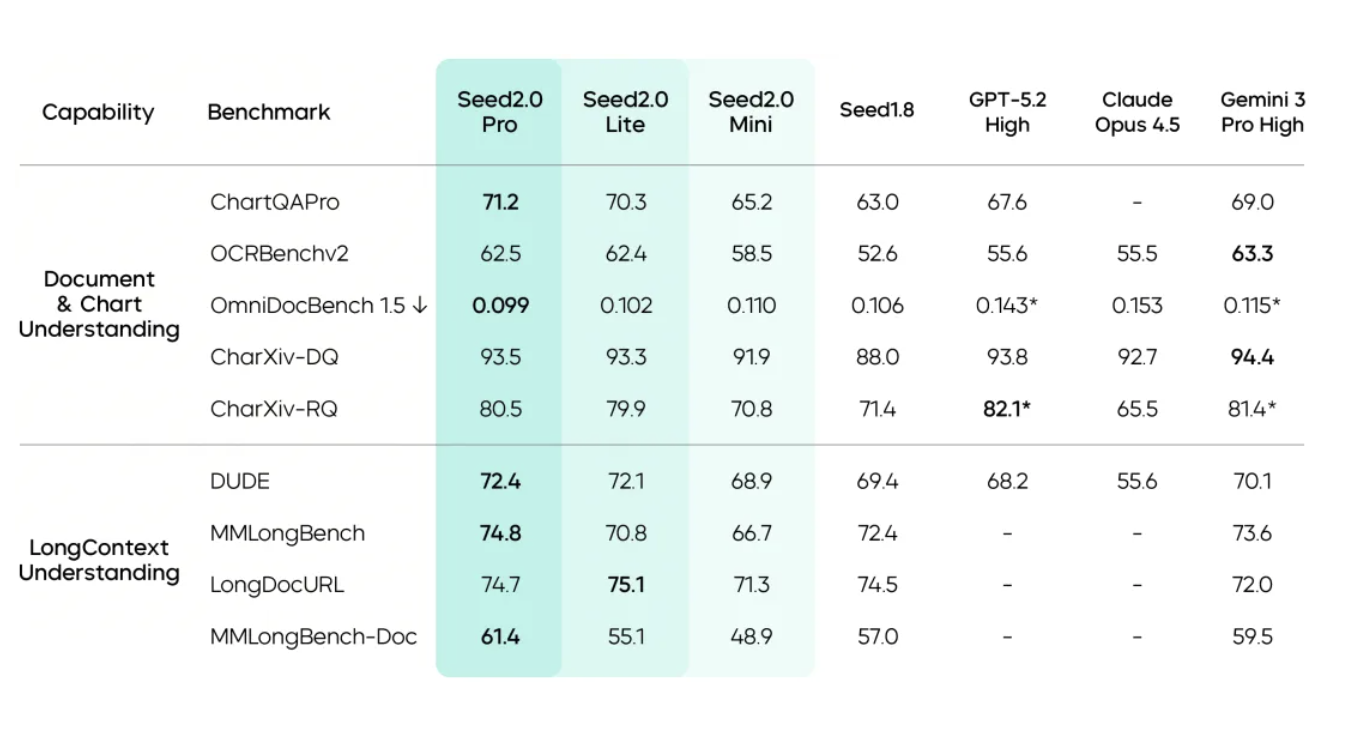
这对应了官方数据中提到的 ChartQAPro 和 OmniDocBench 1.5 的顶尖水准——它不仅在看,而且在理解信息的层级关系。
这种「理解力」放在工作场景里就是生产力。
大量的真实用户查询涉及复杂的图片——截图、图表、扫描文档。我试着把一份关于豆包大模型 2.0 自身的技术文档扔给它,要求进行解析。结果没想到,它不仅提取了关键信息,还搭配脑图和 PPT 生成,形成了一整套比较完整的框架。
甚至在视频理解上,它也展现出了「追剧党」的潜质。技术报告中提到,豆包大模型 2.0 在 EgoTempo 基准上超过了人类分数。
真的比人强?我们扔给它一张《何以笙箫默》的剧照,问:「从这张照片中,可以看出男人是南方人还是北方人?」

这是一个典型的「视觉 + 知识 + 推理」的混合考题。豆包大模型 2.0 的反应非常快,不仅认出这是电视剧《何以笙箫默》及演员钟汉良,也结合原著设定给出了一份深入且清晰的分析报告。
甚至在长视频理解上,它在 TVBench 和 MotionBench 上的高分也体现在了实测中:它能从一段长视频里精准分析动作节奏。对于需要处理监控流、体育赛事分析的行业来说,这含金量要高得多。
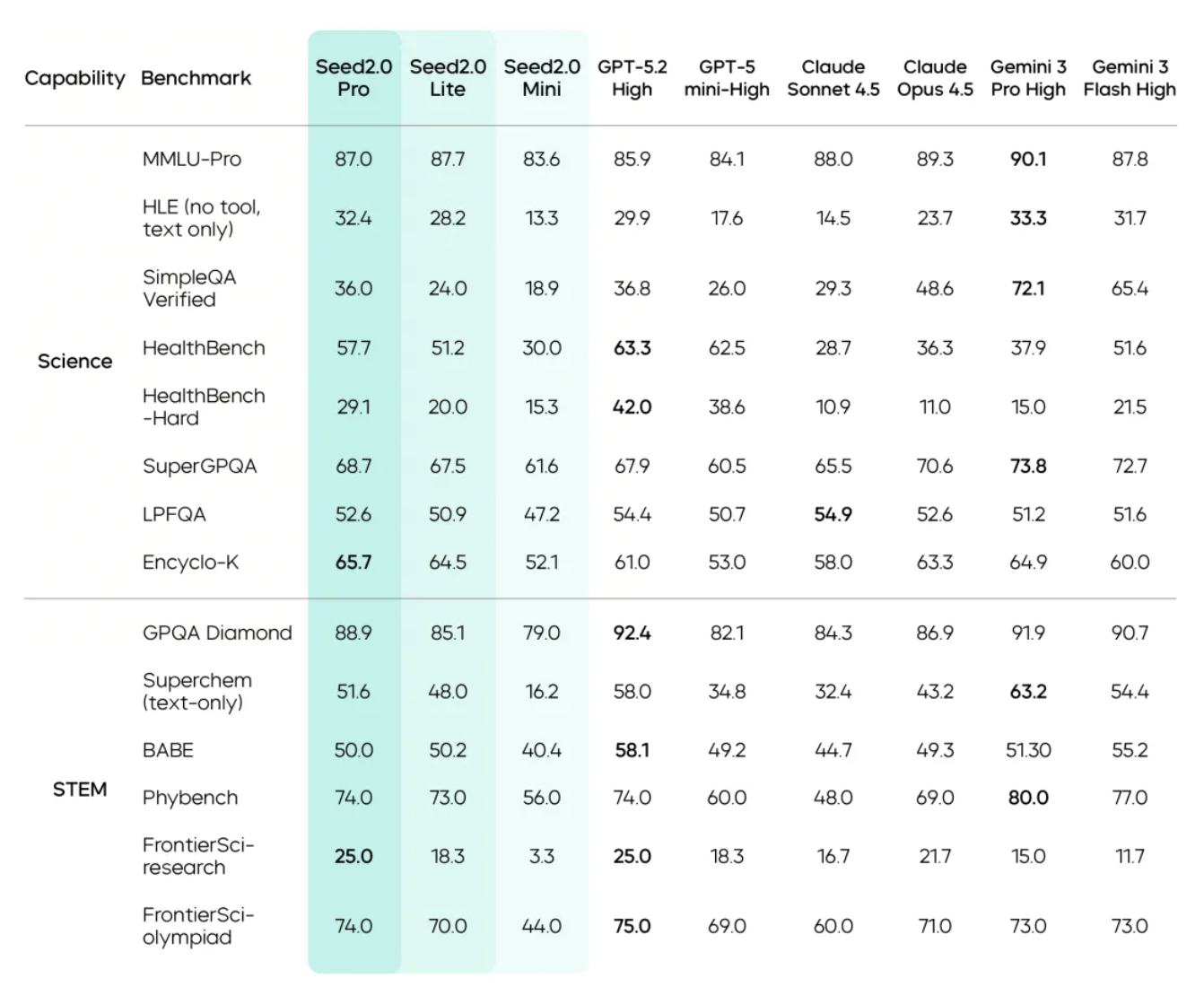
科研级大脑遇上生活小白
在逻辑推理方面,基准测试结果显示,豆包 2.0 Pro 在 SuperGPQA(研究生级问答)上分数超过了 GPT-5.2,在 IMO(国际数学奥林匹克)测试中更是获得了金牌成绩。
无论是「孙悟空既然学了长生术,为何 342 岁还是阳寿已尽?」,还是「两把武器,一把攻击 1~5,一把 2~4,从数据角度,哪把更厉害?」这些问题,显然都不会难倒豆包。
不过,就是这样一个能解奥数题的「学霸」,却在一道 50 米洗车常识题「我想去洗车,洗车店距离我家 50 米,你说我应该开车过去还是走过去?」依旧回答错误。

正常人想的是,开车去,不然洗啥?豆包 2.0 Pro:陷入了深度的「过度推理」。它开始分析距离成本、步行健康收益、车辆启动损耗……最后一本正经地建议我走过去。
这也是当前大模型普遍存在的问题,即便它们拥有科研级的推理能力,但依然缺乏基于物理世界的常识性直觉,只能说是任重而道远。
能帮你早下班的 AI 才是好 AI
这次更新最大的野心,其实在于 Agent(智能体)。Seed 团队发现了一个痛点:模型能做题,但干不了长链路的(比如写一个完整的 APP,或者设计一个实验)。
为了解决这个问题,豆包大模型 2.0 重点强化了指令遵循和长程任务。在 HealthBench 上拿到第一名,在 FrontierSci 上表现强劲。
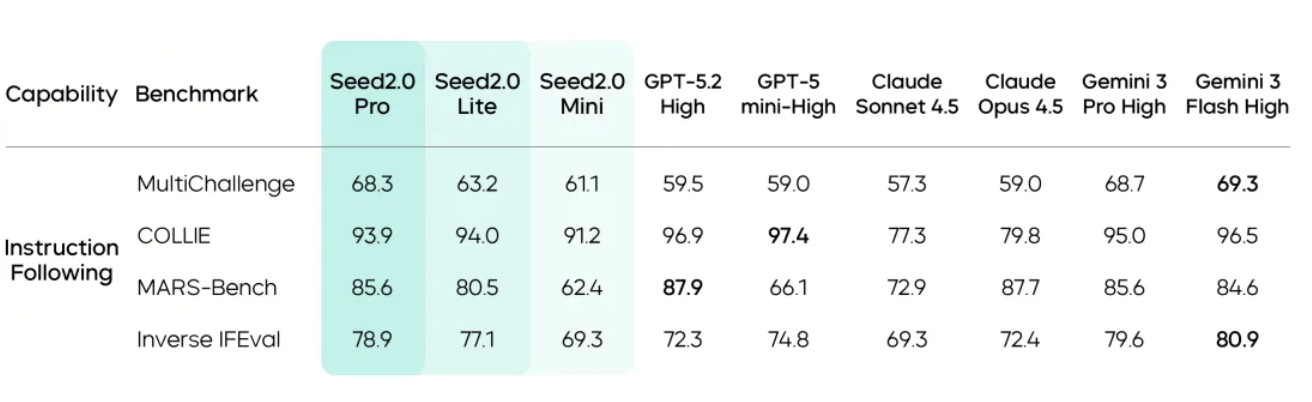
体现在实测中,就是它真的能当「科研助理」用了。把一个生物学难题——「高尔基体蛋白分析」扔给它时,它没有泛泛而谈。它不仅给出了总体路线,甚至把基因工程、小鼠模型构建、多组学分析串成了一条完整流程。
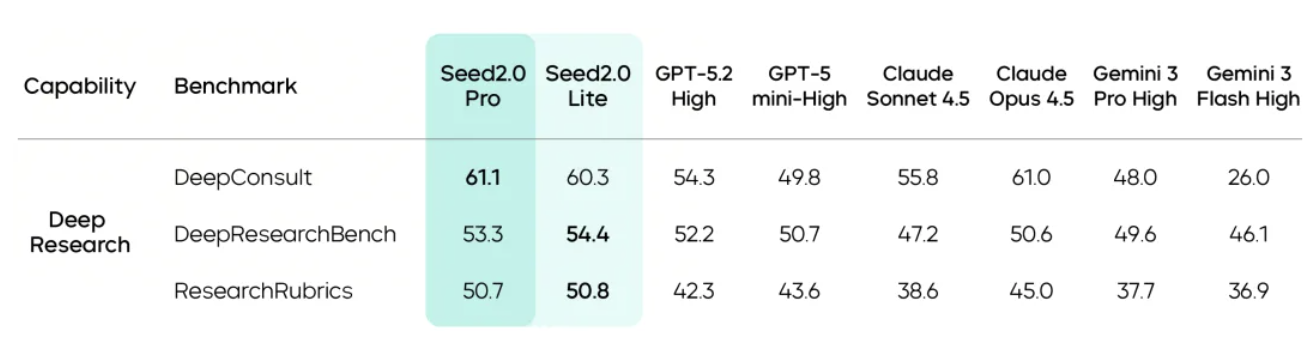
至于编程方面,为了验证豆包大模型 2.0 的「含码量」,我们直接打开了字节自家的 IDE —— TRAE,调用了专门针对编程优化的 Doubao-Seed-2.0-Code。
比如让它使用 p5js 创建令人惊叹的多色交互式动画,效果相当不错。代码一次跑通,屏幕上涌动的色彩不仅流畅,而且交互逻辑完全符合预期。
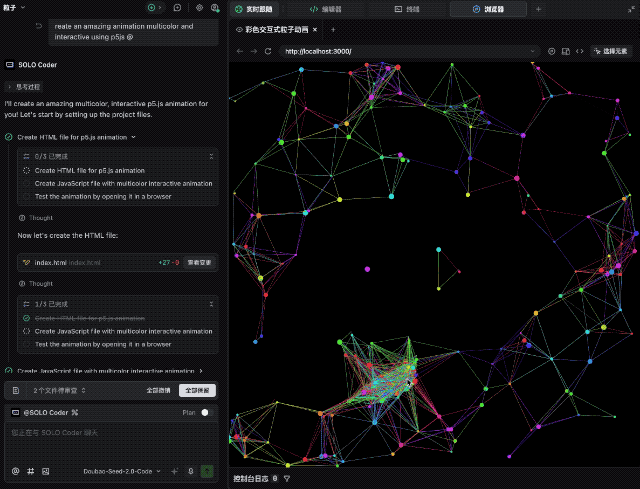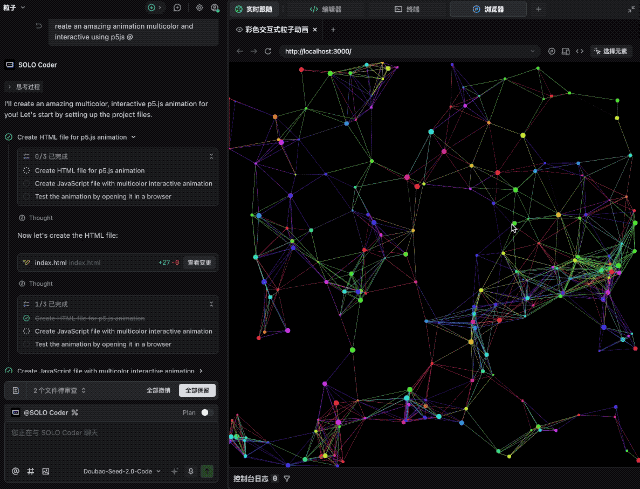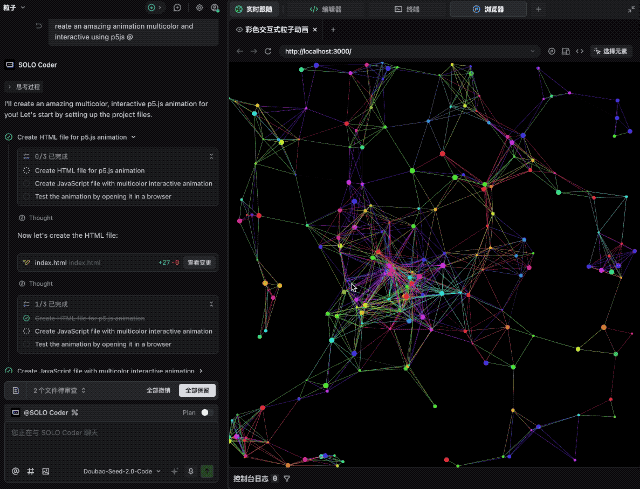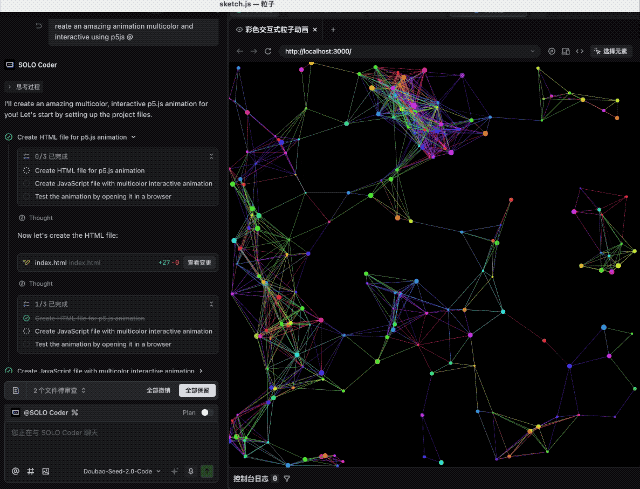
接着,我们要求它用纯代码手搓一个 macOS 的桌面系统。Dock 栏的动效、窗口的层级、顶部的菜单栏,完成度较高,不过审美还有待提高,整体表现中规中矩。
正如豆包大模型团队在其模型卡中所说:
需要注意的是,Seed2.0 系列与国际前沿的大语言模型仍存在差距。Seed 已明确提升模型应对现实世界复杂性的能力方向,并为此在相关方面投入大量精力,对 Seed 模型系列进行优化。
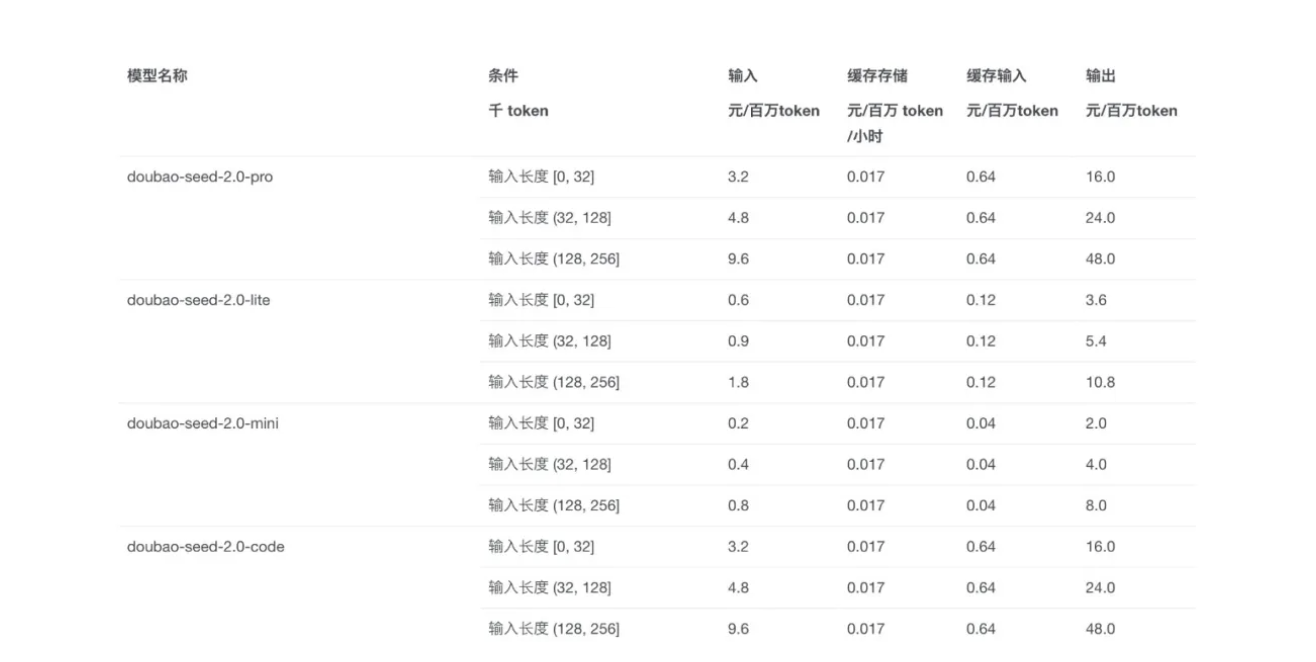
但这一切在价格面前都不重要了。因为豆包大模型 2.0 在提升性能的同时,Token 定价降低了约一个数量级。
这是一个非常现实的商业逻辑。当推理成本更具性价比,很多诸如全量的文档分析、实时的视频流监控的场景,突然就变得可行了。
图片
结合那份长长的基准测试报告,我最大的感受是两个字:务实。它并不完美,但对于打工人来说,一个能帮你读懂图表、能写出扎实代码、且价格划算的 AI,或许会实用得多。
毕竟,能帮我们早点下班的 AI,才是好 AI。
附 79 页 Model Card:
https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/0214/Seed2.0%20Model%20Card.pdf
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。

